Stochastic optimal control - a way to find happiness?
-
As humans, we like to plan our lives and control where they are going. Realistically, however, most things are subject to randomness (“stochasticity”) that we cannot influence. All we can do is to plan our actions to make the best of any given situation. And luckily, control theory is here to help us find the best action plan.
For a more concrete example, imagine you want to optimise your social interactions, i.e. how often you meet your friends, to maximise your own happiness. You can influence your own actions, but the actions of the people around you are beyond your control.
Everyday, you can either stay at home or try to meet a friend. Not having enough time for yourself will render you an unpleasant person that nobody wants to meet with. Not meeting a specific friend for a long time deteriorates the friendship. A successful meeting at the right time will benefit that friendship. Depending on the friend, there is a higher or lower chance that the meeting will (not) happen.
How should you act to have good relationships and optimise your overall happiness?
-
Mathematically speaking, this type of problem can be stated as a Markov Decision Processes (MDP). An MDP comprises four elements:
1) A state space, which consists of all possible states that the system can assume. Here: the status of the relationships with your friends.
2) A set of actions per each state, which includes all possible actions that can be taken in a given state. Here: to try to meet a specific one of your friends or stay at home.
3) A cost or reward map, which associates a cost or reward to each state and/or action. Here: the happiness derived from your overall social life.
4) A discount factor, which regulates how much more the costs or rewards that are closer in time weigh compared to those incurred later on. Here: you care more about your happiness in the upcoming weeks than many years from now.
-
Once the problem is formulated in this way, dynamic programming, a mathematical optimisation method, can be used to compute the optimal action plan for any given state of your system - whether to stay at home or which friend to call - to optimise your overall happiness.
-
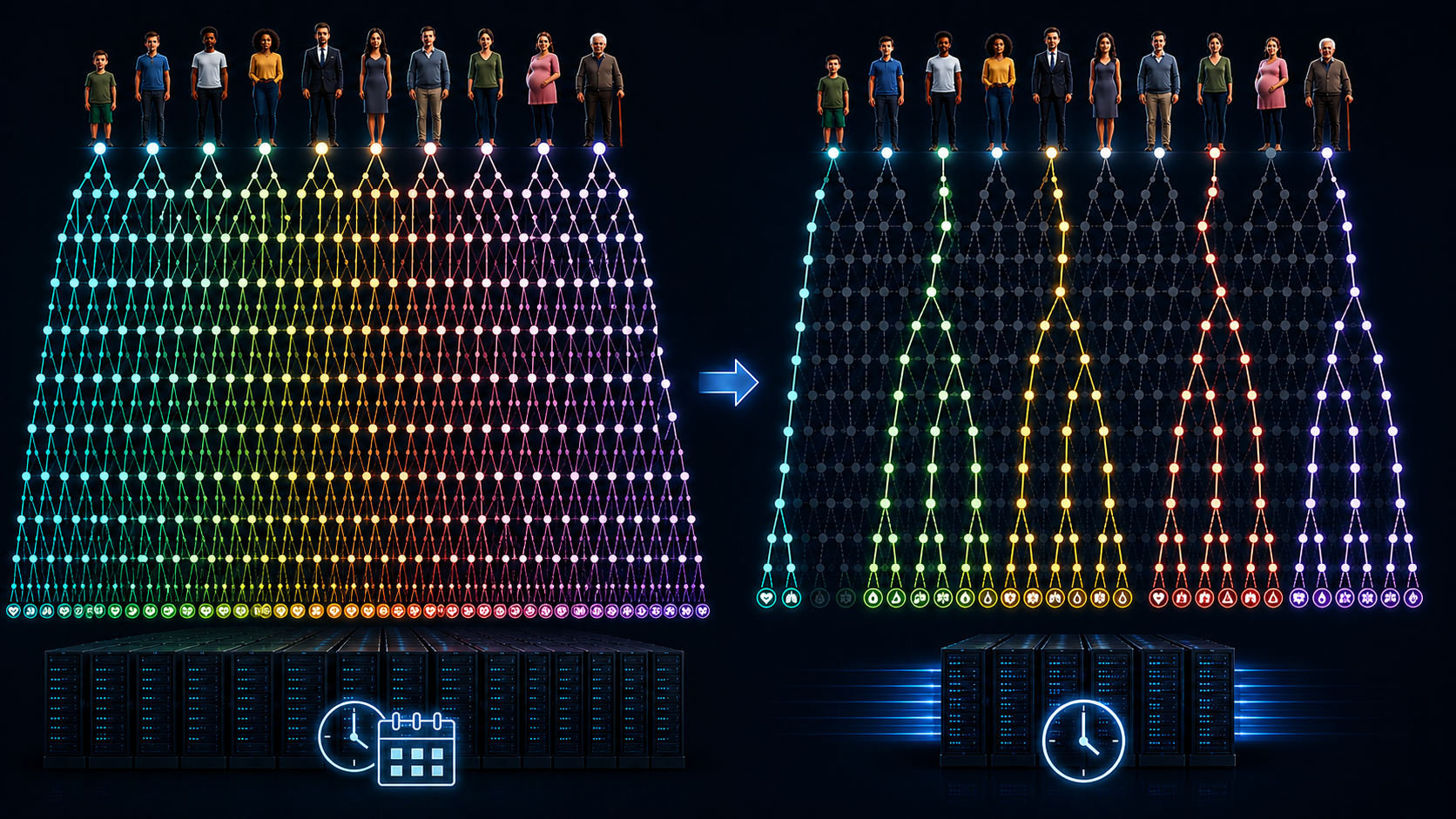
As with all dynamic programming, the curse of dimensionality is a problem. To find the optimal policy, at every step all the possible actions and consequences have to be considered. In our example, if you have two friends, you have three options for the next day: visit friend A, visit friend B, stay at home. For the day after, you again have three options. This makes a total of 3x3 options for only two days. If you look 10 days ahead, you have 3^10 (~59’000) options. If you have 10 friends instead of 2, you have to explore 11^10 (~26bn) options. It very quickly becomes very hard to consider all the options.
-
Current research within the NCCR Automation focusses on computational methods to overcome the curse of dimensionality for bigger and bigger problems and be able to tackle larger-dimensional MDP formulations.
Check out Madupite, one of our Open Science projects, and learn more about our efficient, user-friendly MDP solver.











Decision making for cascading uncertainty - by Mengmeng Li